The first person to explain answer set programming (ASP, pronounced ‘ay ess pee’) to me (Joe Osborn) told me about the three line implementation of graph coloring and the termination guarantees. Like any PL person, I recoiled in horror: you have an always-terminating language where I can solve NP-complete problems in three lines? So every time I write a program of three lines or more, I have to wonder… how exponential is this? No thank you!
I was wrong. Answer set programming is fast and easy to use; it’s a cousin to SAT that offers different tradeoffs than SMT, and I think PL folks have a lot to gain from ASP. As some evidence in that direction, let me tell you about an upcoming paper of mine appearing at POPL 2023, with Aaron Bembenek and Steve Chong.
From SMT to ASP: Solver-Based Approaches to Solving Datalog Synthesis-as-Rule-Selection Problems
https://greenberg.science/papers/2023popl_asp.pdf (artifact https://zenodo.org/record/7150677)
Aaron Bembenek, Michael Greenberg, and Stephen Chong (POPL 2023)
Datalog synthesis-as-rule-selection
Our paper is, on the face of it, about a program synthesis problem for Datalog: given a collection of candidate rules and an input/output example, select the candidate rules that transform the input to the output. The previous state-of-the-art (ProSynth) used a CEGIS loop: use Z3 to guess some rules, try it in Soufflé, use why- and why-not provenance to feed information back to Z3 to make a better guess. Our work gives three new solutions to the problem:
- Datalog as a monotonic theory in SMT. Monotonic theories get a big performance boost, and modern solvers like Z3 and CVC4 support them. And Datalog is the monotonic theory ne plus ultra: we [read: Aaron] wrote Z3 and CVC4 plugins that turn any Datalog program into a monotonic theory. You can use this to do the CEGIS loop with a single call to SAT (but many calls to Datalog).
- Using loop formulae to force SMT to find a least stable model. Every Datalog program has a logical denotation as the least model satisfying its Clark completion. Borrowing from ASP implementation techniques, we can use the Clark completion extended with loop formulae to rule out the hallucinatory models SMT is prone to finding. You can use this approach to do the CEGIS loop with not so many calls to Datalog, but possibly many calls to SAT.
- Just encode it in ASP. The conventional ASP implementation strategy (grounder and solver) found in tools like clingo admits a direct encoding of the synthesis problem; our translator is just 187 SLOC. ASP lets you name that tune in just one note: you call the grounder, then you call the solver, and then you’re done.
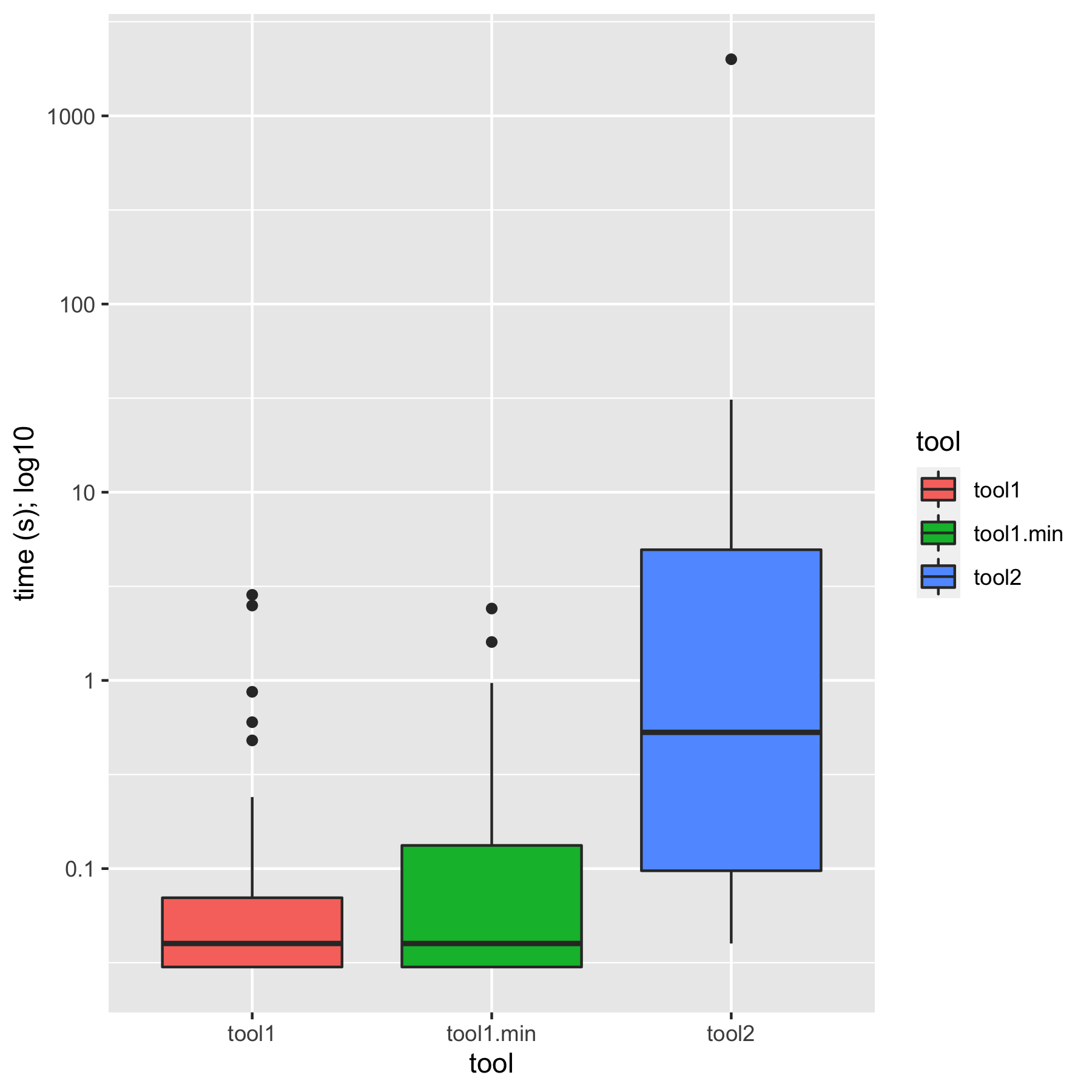
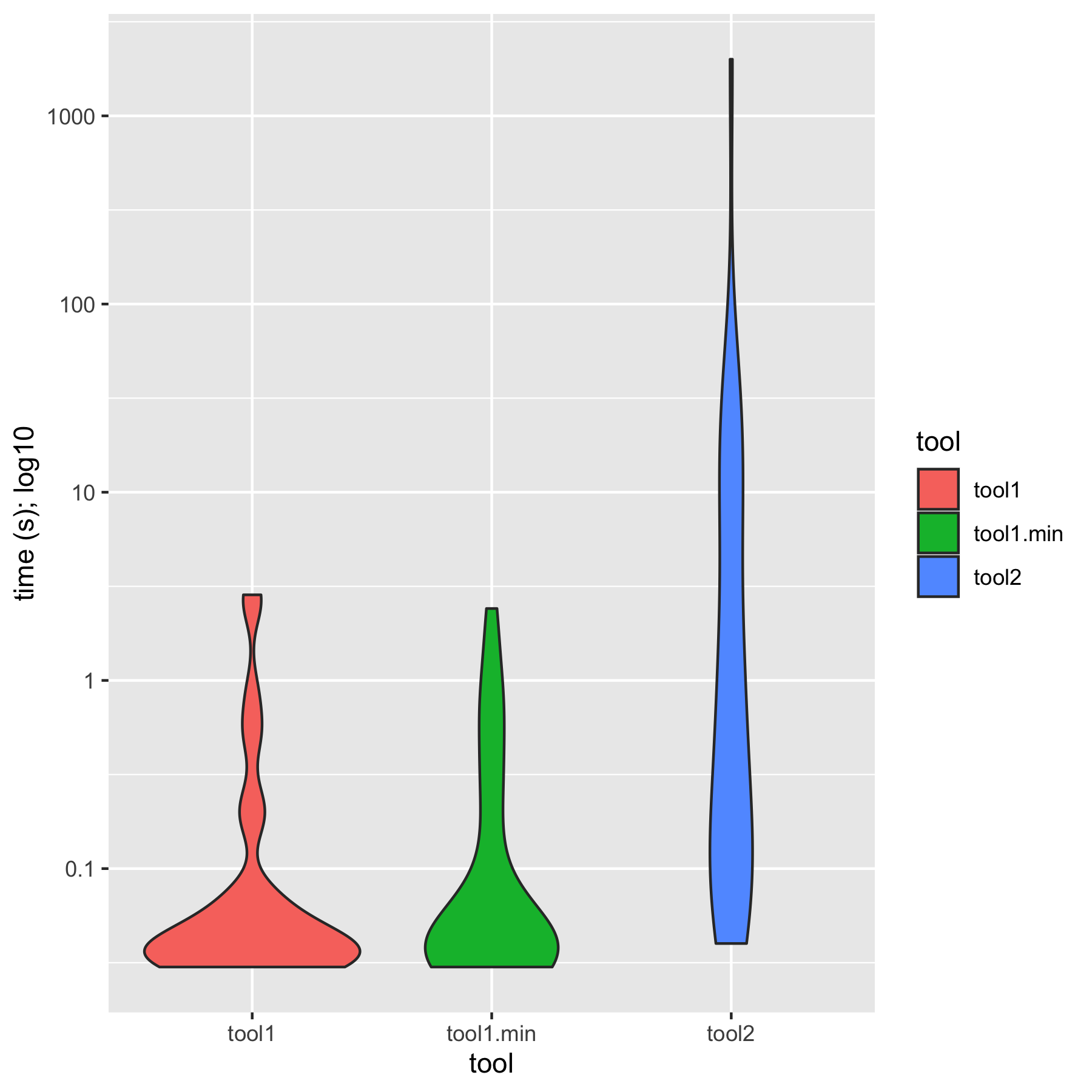
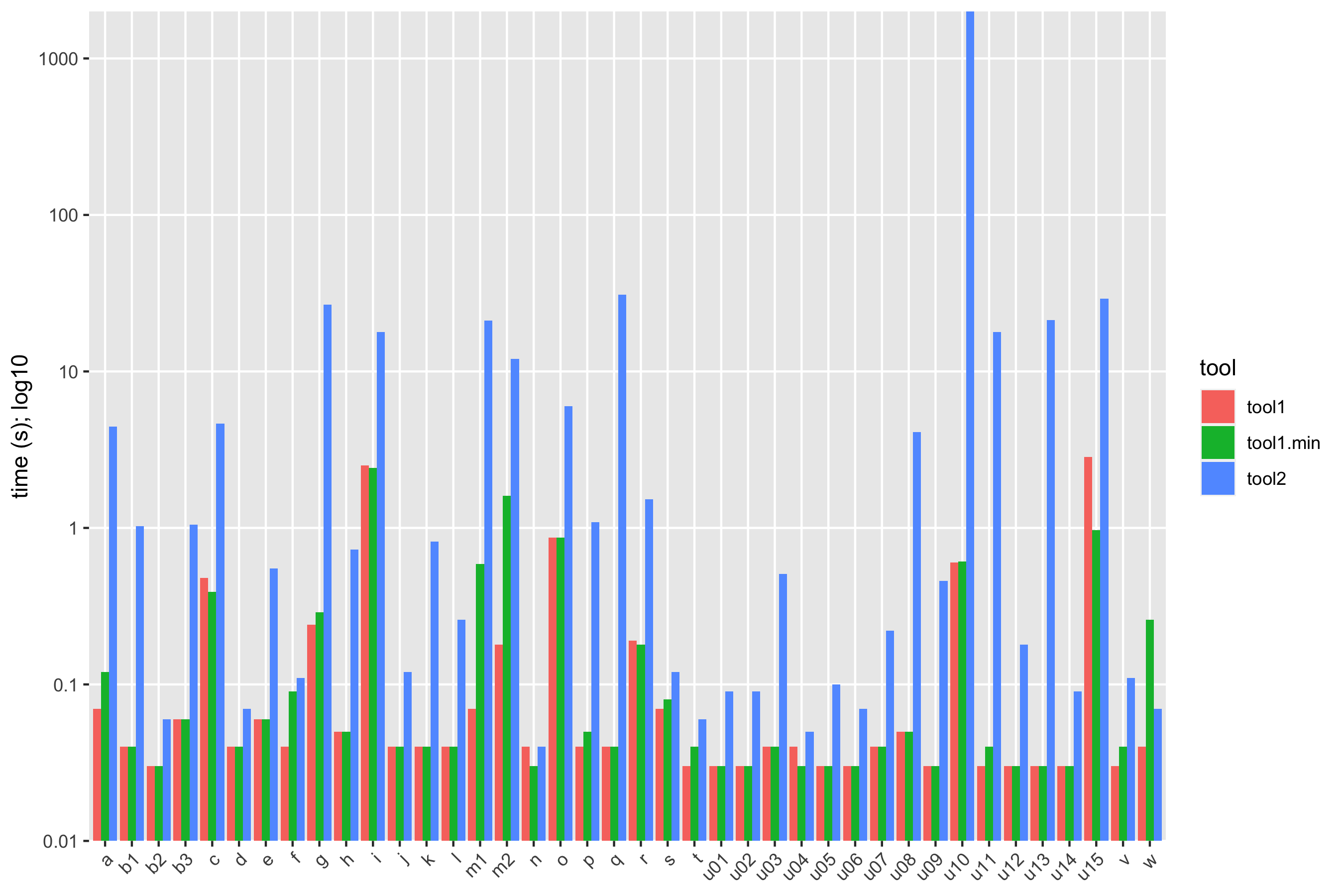
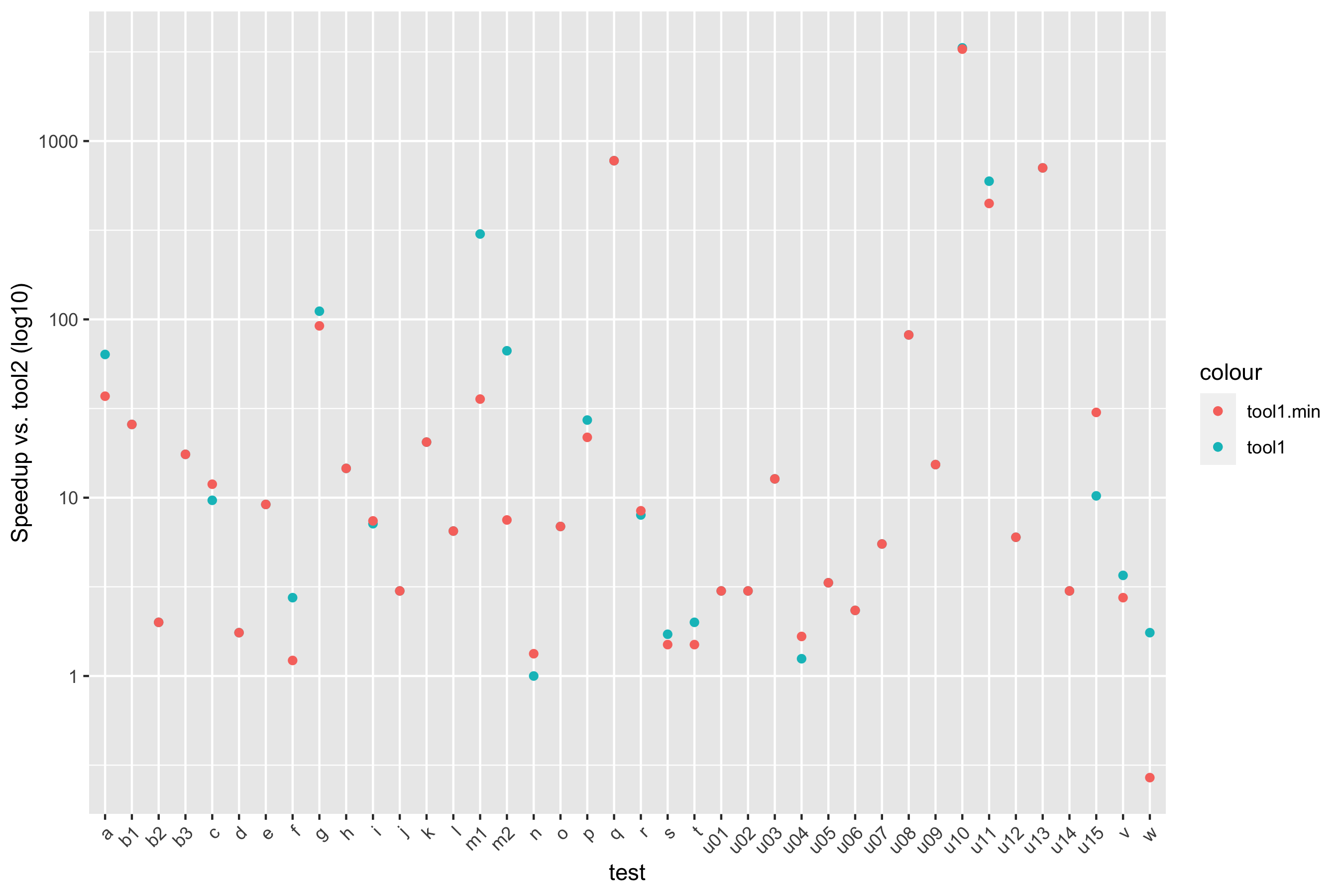
The gist of it is that the ASP solution is not only vastly simpler than the others, it outstrips them in performance, showing a ~9x geomean speedup compared to the state of the art. (I wrote previously about how to summarize early versions of these numbers.) Practically speaking, the ASP synthesizer always returns in under a second, while every other solution shows slowdowns on some of the benchmarks, taking tens of seconds or even timing out at ten minutes. There’s lots more detail in the paper.
I should add that the existing benchmarks are pretty easy: the examples are small, with example facts and candidate rules numbering in the low hundreds. In this setting, anything more than a few seconds isn’t worthwhile. We have some more criticism of the problem setting in the paper, but I can sum up my feeling as: when confronted with the benchmark challenge of implementing strongly connected components (SCC) in Datalog, who has the technical capacity to (a) write up an input/output example for SCC for a non-trivial graph, (b) generate several hundred candidate rules, (c) install and run a program synthesis tool, and (d) verify that the resulting program generalizes but (e) lacks the technical capacity to simply implement SCC in Datalog? Transitive closure is the “Hello World” of Datalog; strongly connected components is the “Fahrenheit-to-Celsius” of Datalog. The benchmarks don’t characterize a problem that anyone needs to solve.
Answer Set Programming
While I’m proud of the contributions outlined above, I’m most excited about introducing ASP to a broader audience. It’s a historical accident that ASP is more or less confined to the AI subfield, where a lot of great SAT and SMT research continues apace—not to mention the program synthesis work published at venues like AAAI and IJCAI under the umbrella of ‘inductive logic programming’. (Any PL person working on synthesis should look closely at Popper and ILASP.)
Our paper goes into more detail, but I like to contrast ASP with SMT by talking about justification. ASP will find solutions that are in some sense well justified by your problem statement (formally, it will find stable models); SMT has no such guarantee.
SMT solvers do an incredible job of finding witnesses for existentials: just (declare-const x Foo) and SMT will find your Foo, no problem. Well, maybe a problem: SMT’s approach to finding an x of type Foo is to go into the desert on a vision quest—it’ll keep hallucinating new values for x until it finds a satisfying one. On the plus side, that means SMT can find an x that doesn’t appear anywhere in the constraints you gave it. On the minus side, that means SMT is straight up hallucinating values—and you’re the one controlling set and setting to make sure SMT stays this side of sanity.
ASP never hallucinates. If something is in an answer set, it’s there for a reason. ASP’s non-monotonic semantics lets you freely mix negation and recursion (unlike Datalog, which forces negation to be stratified); the stable model semantics guarantees you won’t get nonsensical, circular answers that justify their premises with their conclusions.
Put simply: ASP is a SAT-like discipline that lets you work efficiently and correctly with inference rules. SMT is a SAT-like discipline that lets you work efficiently and correctly with existentials over equality and theory predicates. PL work needs both styles of reasoning; as we’ve shown, ASP can bring simple solutions and startling efficiency over complex appoaches using SMT. Maybe it’ll work for your problem, too?